DreamFusion: Text-to-3D via Score Distillation Sampling
Poole, Jain, Barron, Mildenhall — Google Research, arXiv:2209.14988 (ICLR 2023)
Explained assuming: you know NeRF, differentiable rendering, marching cubes, shading. You don't (yet) know diffusion models.
The setup you already know
You have a NeRF — an MLP mapping a 3D point to (density, color) — rendered via
standard volume rendering (ray marching + alpha compositing) to produce an image from any camera pose.
Normally you'd fit this MLP the usual NeRF way: multi-view photos + a photometric loss.
DreamFusion has no input photos at all. Just a text prompt. The "loss" that tells the
NeRF whether a rendered view looks right comes from a pretrained 2D image model instead of from
ground-truth pixels.
Diffusion models, from scratch
A diffusion model is trained to do one thing: given a noisy image x_t (the original image
x_0 mixed with Gaussian noise at "noise level" t), predict what noise was added.
It's a big convolutional network (a U-Net). Feed it x_t, t, and a text embedding
y; its output ε̂(x_t, t, y) is a guess at the noise vector that was
mixed in. Trained on billions of (noisy-image, noise, text) triples, this becomes very good at
"denoising toward things that look like y."
Normal use: start from pure noise, call the network ~50–1000 times, each time removing a bit of predicted noise — that's "sampling." DreamFusion does not do this sampling loop. It uses the network's single-shot output differently (see SDS below).
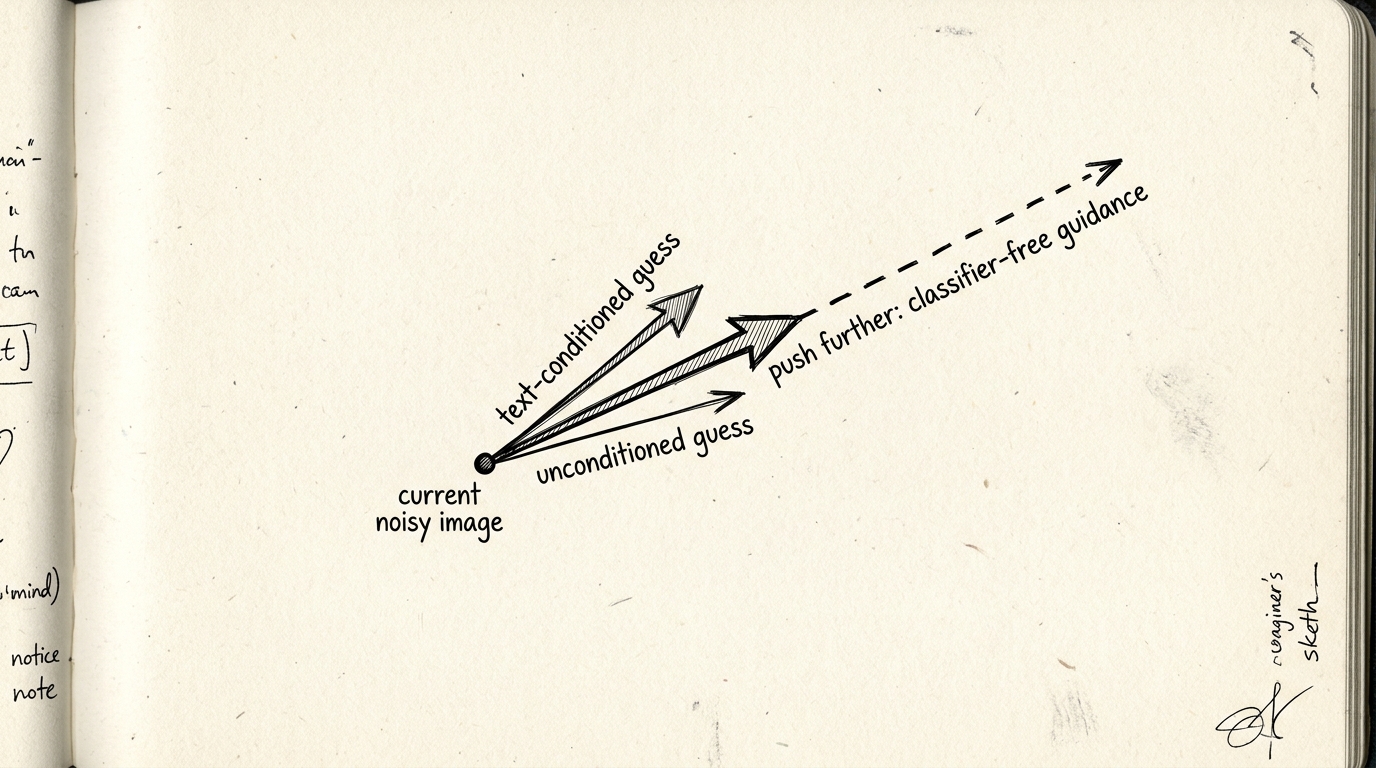
One more mechanism: classifier-free guidance. At inference you query the network twice — once with text conditioning, once without — and extrapolate away from the unconditional prediction toward the conditional one, scaled by a guidance weight. Cheap trick, sharpens text-adherence at some cost to realism/diversity. DreamFusion cranks this weight far higher than normal image generation (~100 vs. the usual ~7.5), because it needs a strong, unambiguous gradient signal for optimization, not a nice-looking single sample.
The optimization loop
Step by step
- Sample a random camera (position, elevation, azimuth) and light — same idea as picking training views, except here you choose where to render from; there's no fixed training set.
- Render the current NeRF from that camera → image
x. Ordinary differentiable volume rendering, identical to NeRF training. - Add Gaussian noise to
xat a random timestept:x_t = x + ε(mimics the forward noising process the diffusion model was trained on). - Feed
x_tinto the frozen U-Net (frozen = no training/backprop into its weights — it's a fixed differentiable critic), getε̂(x_t, t, y)with classifier-free guidance on prompty(augmented with "front/side/back/overhead view" per the sampled camera angle — the main defense against the multi-face "Janus problem"). - The key move. The "correct" thing would backprop through the entire U-Net back to the
image — expensive, and empirically gives bad gradients here. DreamFusion drops that expensive
U-Net-Jacobian term algebraically. What's left: the gradient on the rendered image is just
(ε̂(x_t,t,y) − ε)— predicted noise minus the actual noise you added in step 3, weighted by a factor depending ont. One forward pass through the U-Net, no backward pass through it. This is the entire SDS loss — it's defined directly as a gradient, not as a scalar you'd write down and differentiate normally. - Chain that pixel gradient back through the differentiable renderer (exactly like a photometric-loss gradient) into the NeRF MLP's weights, take an Adam step.
- Repeat for ~10,000s of iterations, fresh random camera/light/noise-level every time.
Regularizers (pure graphics, no DL needed)
- Orientation loss: penalizes normals facing away from the camera on visible surface — stops degenerate inside-out geometry.
- Textureless shaded renders: some fraction of iterations render "shaded-only, no albedo" versions of the same viewpoint, specifically so the diffusion critic can't be fooled by painting fake bumpy detail onto flat geometry via texture alone — forces some of the gradient signal to actually shape the density field, not just the color field.
- Opacity/transmittance regularization: encourages a compact, non-fog-like density field.
After optimization
Extract a mesh via marching cubes from the converged density field — same as any NeRF-to-mesh pipeline you'd already build by hand.
Known failure modes
| Symptom | Cause |
|---|---|
| "Janus problem" — multiple faces/heads on one object | View-conditioning by text hint is a crude disambiguator, not real multi-view consistency. |
| Oversaturated, waxy shading | Side effect of the very high guidance weight needed to get a usable gradient at all. |
| Low shape diversity per prompt | SDS gradient-ascends toward high-likelihood regions of the guided model rather than actually sampling its distribution — it collapses to one "consensus" mode. |