MeshAnything V2: Artist-Created Mesh Generation via Adjacent Mesh Tokenization
Chen, Wang, Luo, Wang, Chen, Zhu, Zhang, Lin — arXiv:2408.02555 (2024)
Explained assuming: you know meshes, point clouds, vertices/faces/normals at a working level — not a
graphics expert. You're newer to deep learning: transformers, tokens, embeddings, and autoregressive
generation explained from scratch below.
The problem it solves
Most automated 3D generation — NeRF, 3D Gaussian splatting, implicit SDF/occupancy fields extracted via marching cubes — produces what this paper calls an "algorithm-generated mesh" (AGM): a dense, uneven triangle soup with no clean structure. It renders fine, but it's painful to actually work with — hard to rig, animate, edit, or texture by hand.
An "artist-created mesh" (AM) — the kind a human 3D modeler makes — instead uses a small number of faces (hundreds, not hundreds of thousands), mostly quads/n-gons rather than pure triangles, with edges deliberately aligned to the shape's actual geometric features (corners, silhouette edges, part boundaries).
MeshAnything's goal: given any 3D shape, regardless of how it was produced, generate a plausible artist-style retopology of it. It's a retopology/regeneration step, not a from-scratch shape generator — the shape already exists (as a point cloud); the model's job is purely to decide where a human-style mesh's vertices and faces would go on that shape.
Deep learning concepts, from scratch
Tokens and vocabularies
A "token" is just a discrete symbol drawn from a fixed, finite list (a "vocabulary"). Text models split
sentences into sub-word tokens (e.g. "unhappiness" → un + happi +
ness), each with an ID number the model can put a probability on. Mesh vertex coordinates are
continuous floating-point numbers, which don't fit that scheme directly — so MeshAnything
quantizes them: it snaps each coordinate onto a fixed discrete grid (think: rounding to
the nearest of a few hundred allowed values along each axis). Once coordinates are discrete, they can be
treated as vocabulary entries, exactly like word-pieces, and the same machinery used for language models
applies.
Autoregressive generation (the language-model mechanism)
"Autoregressive" means: predict one token, append it to what's been generated so far, then predict the next token conditioned on everything generated up to that point — repeat until a special "end" token comes up or a max length is hit. This is exactly how a chatbot generates a reply one word-piece at a time. MeshAnything applies the identical mechanism, except its vocabulary is quantized mesh geometry (vertex coordinates and structural marker tokens) instead of English word-pieces. At each step the model outputs a probability distribution over the vocabulary; a token is sampled (or the most likely one is taken); that token is fed back in as input for predicting the next one.
This is a fundamentally different generative mechanism from Score Distillation Sampling (SDS)-based 3D generation: there, a fixed-size set of continuous parameters (e.g. a NeRF's weights) is nudged by gradient descent over thousands of iterations, using a frozen 2D diffusion model purely as a critic supplying a gradient. Here, the model itself directly emits the output, symbol by symbol, the same way it would emit a sentence.
Embeddings / latent codes (how the point cloud gets "read")
An embedding (also called a latent code) is a vector of numbers produced by a neural network that summarizes some input in a form other networks can consume — conceptually similar to how a CLIP model turns an image into a vector that captures "what's in it" without being the pixels themselves. MeshAnything uses a separate, frozen, pretrained point-cloud encoder network (trained once elsewhere, not touched further here) that reads the input point cloud (8192 points, each with xyz position + a surface normal) and compresses it into a compact set of shape-embedding vectors capturing the target geometry.
Cross-attention (how generation stays grounded in the input shape)
"Attention" in a transformer is a mechanism for letting one token look at other tokens/vectors and decide which are relevant to it right now. Self-attention = a token looking at the other tokens already generated in its own sequence (needed just to keep the mesh internally consistent). Cross-attention = a token looking at a completely different set of vectors from another source — here, the frozen shape embedding from the point-cloud encoder. Every time the decoder is about to emit the next mesh token, it cross-attends to the shape embedding, which is what keeps the generated mesh actually shaped like the input point cloud instead of some generic mesh unrelated to it.
How it's trained (the other big contrast with SDS)
MeshAnything's transformer weights are trained once, offline, on a large dataset of real (point cloud, artist-made mesh) pairs. Training uses ordinary supervised next-token cross-entropy loss ("teacher forcing"): feed the model the correct tokens generated so far, ask it to predict the next one, compare its predicted probability distribution against the actual next token in the real mesh, backpropagate, repeat over the whole dataset. This is precisely how large language models are trained on text — same loss function, same idea, different vocabulary.
Architecture / pipeline
merge_vertices(), remove degenerate/duplicate faces — ordinary mesh cleanup, not a
deep-learning step — giving the final artist-style mesh (≤1600 faces).Adjacent Mesh Tokenization (AMT) — V2's actual contribution
The naive way to tokenize a mesh (used by V1 and by the earlier MeshGPT paper it builds on): emit every face as 3 full vertices — 9 numbers — independently. The problem: in a real mesh, most consecutive faces (in a sensible traversal order) share an edge, meaning they share 2 of their 3 vertices with the previous face. Emitting all 9 numbers per face re-sends coordinates that were just emitted moments ago — wasted tokens, in a transformer whose sequence length is a hard, fixed budget.
AMT orders faces via a specific traversal so that, whenever the next face shares an edge with the current one, only the new, not-yet-seen vertex needs to be emitted — the shared ones are implicit from the adjacency structure already established. This roughly halves the average number of tokens needed per face.
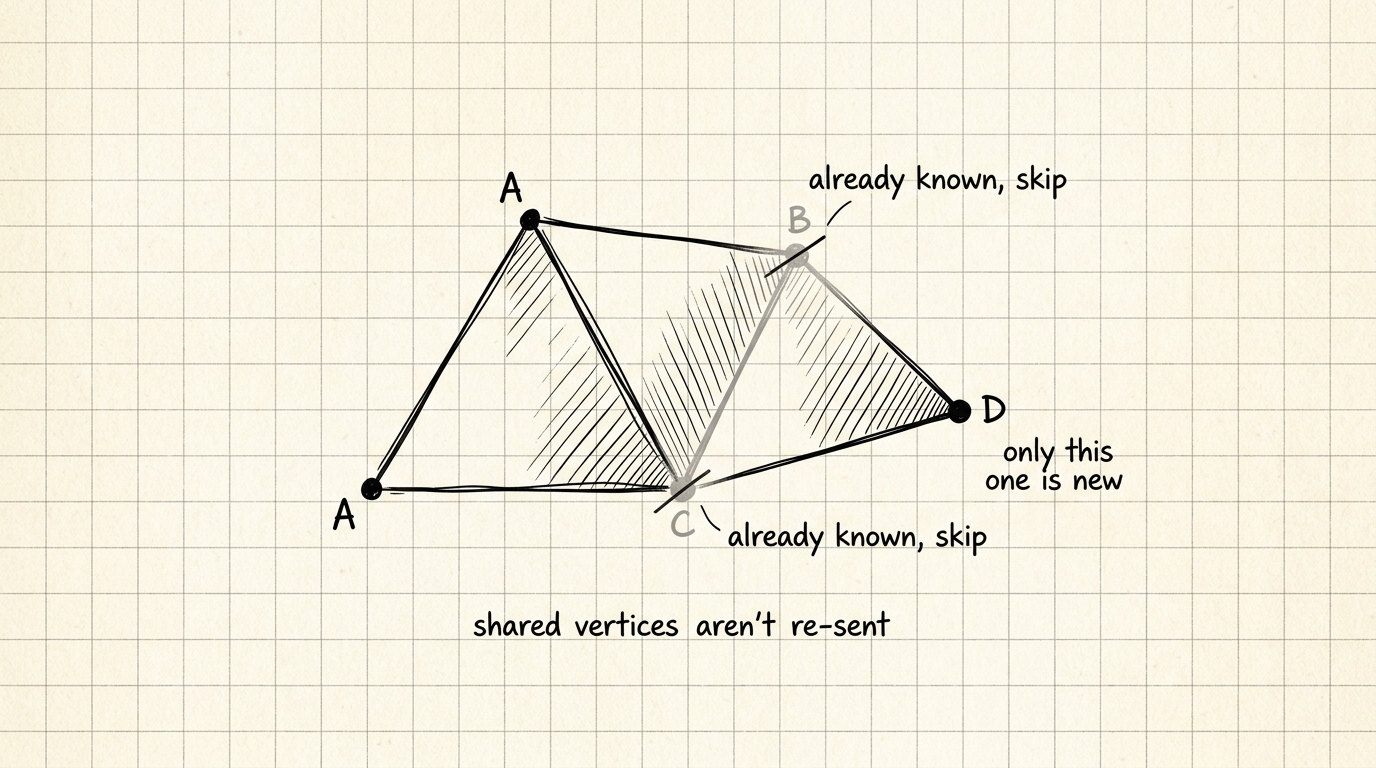
Why this matters concretely: a transformer's context window (max sequence length) is fixed. Halving the tokens-per-face means the same context window can represent roughly twice as many faces — which is the direct reason V2 raised the practical face ceiling to 1600 faces versus V1's much lower cap. (Analogy, if it helps: like video compression encoding only the pixels that changed between frames instead of re-sending every frame whole — exploiting redundancy between consecutive items instead of encoding each one independently.)
Input / output contract (from the reference implementation)
| Aspect | Value |
|---|---|
| Checkpoint | Yiwen-ntu/meshanythingv2 on Hugging Face |
| Input | point cloud (8192, 6) — xyz + normal, centered on bbox midpoint, scaled to [-0.9995, 0.9995]³, float16, +Y-up |
| Output | flat vertex tensor reshaped to (-1, 9) (3 vertices × 3 coords per face); NaN rows = padding, must be masked |
| Post-processing | merge_vertices + degenerate/duplicate-face removal (matches reference main.py) |
| Face cap | 1600 — a training-distribution limit, not just an inference knob |
| Reference cost | ~8GB VRAM, ~45s/mesh on an A6000 |
Known limitations — and why input quality matters
- 1600-face cap is hard — a property of the training distribution, not a setting you can turn up.
- Topology quality is bounded by training data — quad-dominance and edge alignment reflect what's typical/likely in the artist-mesh dataset it learned from, not a guarantee for any given input.
- Garbage-in-garbage-out sensitivity — since there's exactly one conditioning pass, a low-fidelity input point cloud (e.g. from a raw feed-forward 3D generator) tends to produce a low-fidelity retopology, motivating an input-refinement step (like SDS geometry refinement) upstream of this model rather than after it.